AI is the new OS:
(**Disclaimer**: The views and opinions expressed in the article “AI is the New OS” are solely those of the author, Mike Morley, and do not reflect the views, positions, or opinions of his employer, Arcurve. This article is written in a personal capacity and is intended for informational purposes only. It should not be interpreted as representing the official stance or policy of Arcurve on any matters discussed within.)
Overview:
We have the world of knowledge at our disposal, but it has become nearly impossible for us to effectively harness the knowledge that exists inside of our own personal knowledge stores much less that inside the typical enterprise. This is due to the combination of silos, the tyranny of file folders and applications and user interfaces that have become increasingly complex.
This article explores why this situation has arisen and how Large Language models and AI enhanced operating systems have the potential to recapture the original vision of computing as a means of fostering creativity and knowledge sharing envisioned by Alan Kay (A Personal Computer for Children of All Ages (theartofresearch.org):
“Imagine having your own self-contained knowledge manipulator. Suppose it had enough power to outrace your senses of sight and hearing, enough capacity to store for later retrieval thousands of page-equivalents of reference materials, poems, letters, recipes, records, drawings, animations, musical scores, waveforms, dynamic simulations, and anything else you would like to remember and change. Imagine being able to dynamically share that knowledge with anyone, anywhere across any device. Imagine if it were so easy to program that a child of any age could do it. A safe environment, where the child ‘can assume almost any role without social or physical hurt is important….”
Challenges with Enterprise Knowledge Collaboration:
Computers and mobile devices are truly incredible, and as a person who started their career in the 1980s just as personal computers arrived on the scene, it has been literally mind blowing seeing how fast and how far we have come since I first saw that flashing green cursor on my apple //e back in 1982.

At this time, while there were more powerful computers available mainframes and minis in cities with universities, Barrie Ontario did not have a university, so we were limited to PCs, and had to learn how to use these machines on our own. Fortunately, there were other very smart people who helped me with this when I wrote my first bulletin board system (BBS) →theLink← with Wayne Horodynski and Andrew Leggett.
The BBS project was impressive at the time in that it allowed for a rudimentary form of collaboration and knowledge sharing that people take for granted today with the internet.
These systems were text based though, so it was amazing when seemingly out of nowhere the first LISA and Macintosh systems from apple appeared running the then revolutionary Graphical User Interfaces. The GUI and its desktop file/folder pattern for storing the knowledge and data created by applications was a powerful means of making computing generally accessible.
There were many limitations though to the implementation used at the time. So when the content creation, curation and storage paradigm based on the GUI Desktop metaphor featuring applications and file folder-based pattern became the primary means of creating, storing, organizing knowledge, the limitations of this pattern also became the standard.
While relational databases (which also emerged in the 80s) used to store, manage and retrieve structured data have evolved substantially since that time, the fundamental way we interact with mobile and desktop devices, and how we work with unstructured knowledge using applications and files is still is nearly identical to what it was back in the 80s.
Tim Berners Lee created (The original proposal of the WWW, HTMLized (w3.org)) the hypertext markup language (html) and associated protocol (http) to try to provide a better way of creating and organizing knowledge. His innovation of the hyperlink->page enabled the rapid adoption and growth of the World Wide Web (www). But its success was also predicated on limitations on one-way hyperlinks, allowing for dead hyperlinks and a server based pattern. These decisions were key to its rapid adoption, but ended up spreading the exacerbating the hybrid challenges of complexity of organizing, finding and curating high quality knowledge. Ted Nelson has some excellent articles and interviews on the subject of the issues with WWW style hyperlinks. Tim Berners-Lee has not only written articles addressing the issues, he has also started the Solid Project to try to address the issues. (Tim Berners-Lee Says the Web Has ‘Failed Instead of Served Humanity’ (businessinsider.com))
The complexity created by the web pattern provided the opportunity for organizations like Google and Facebook to create centralized platforms that addressed the problem of finding knowledge. But their utility came with a very high cost to personal data, privacy and the user’s ability to control their data.
While google was able to address the find and discovery challenges of knowledge on the internet, albeit with the downsides introduced by its business model, Googles technology and other search systems like it were not successful solving the issues of finding and discovering knowledge in the Enterprise.
This is because the Application user interface pattern which typically stores data associated with the application in a custom database for said application, are siloed by design. The original File as a container created by applications that deal with documents means that none of the data these systems create are linked as they are in hypertext documents creating a different kind of silo that live inside huge filestores or ‘Drives’.
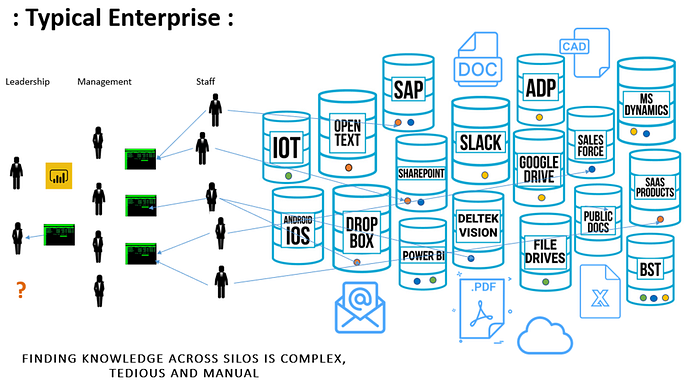
These drives are made up of vast rat’s nests of file folders and failed file naming convention attempts, and of course, the gigantic disgusting mess resulting from anything typical enterprise knowledge management systems touch. The challenges associated with managing all these siloes continue to get worse, as this visualization of a single ‘F-Drive’ from an enterprise illustrates.

The interesting thing is that while our ability to create massive amounts of data to represent the world have improved, the way we interact with our computing devices, and how we store and access the knowledge contained inside these data repositories has not changed since the personal computer first appeared.
Enterprises therefore have become a nightmare of siloed complexity, rendering page rank and other algorithms like it of limited utility in solving this problem.
What Might Have Been: A Brief History of Knowledge Collaboration
““Of all the words of mice and men, the saddest are, “It might have been.” ― Kurt Vonnegut
The original vision for knowledge creation and collaboration was very different than the complexity we live with today. There is an excellent book that goes through the history of knowledge systems and the vision that was lost in the race to commercialize computer technology called The Dream Machine.
“The Dream Machine” by M. Mitchell Waldrop (Amazon.com: The Dream Machine: 9781732265110: Waldrop, M. Mitchell: Books) is a seminal work that explores the life and vision of J.C.R. Licklider, an influential figure in the early development of computers and the internet. Licklider, often referred to as “Lick,” had a profound impact on the field of computing, particularly in his vision of human-computer interaction and the development of knowledge systems.
The book delves into how Licklider envisaged computers not just as computational devices, but as tools to augment human intelligence and facilitate dynamic knowledge collaboration. His ideas were groundbreaking, laying the foundation for what would become the internet and personal computing. (Man-Computer Symbiosis (mit.edu))
Key to Licklider’s vision were concepts of intuitive, user-friendly interfaces and networked computers that could enable unprecedented collaboration and information sharing. He imagined a future where computers would empower individuals to connect, create, and share knowledge in ways that were previously unimaginable.
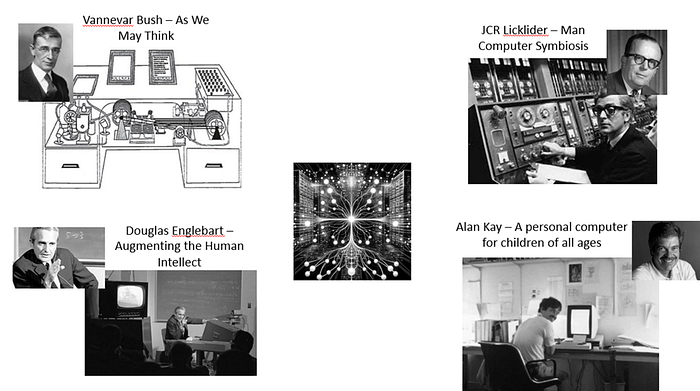
The book also discusses the contributions of Douglas Engelbart and Alan Kay, who were significantly influenced by Licklider’s ideas. Engelbart, famous for inventing the computer mouse, shared Licklider’s vision of computers as tools for augmenting human intellect. His work on the oN-Line System (NLS) was a direct manifestation of this vision, showcasing collaborative, interactive computing. (Augmenting Human Intellect: A Conceptual Framework — 1962 (AUGMENT,3906,) — Doug Engelbart Institute and if you really want your mind blown — The Mother of All Demos, presented by Douglas Engelbart (1968) (youtube.com))
Alan Kay furthered this vision through his work on object-oriented programming and the development of the Dynabook concept, which inspired the design of modern laptops and tablets. Kay’s ideas about personal computing were revolutionary, focusing on ease of use and accessibility for non-technical users. I was fortunate to attend the OOPSLA event in 2004 at which Alan Kay was given the Turing Award for his contributions to computing.
“The Dream Machine” also chronicles how the rush to commercialize these technologies led to a divergence from the original visions of Licklider, Engelbart, and Kay. As the computer industry grew, the focus shifted towards profitability and market dominance. This shift often meant prioritizing more immediate, commercially viable applications of technology over the more ambitious, long-term goals of enhancing human intellect and collaborative knowledge creation.
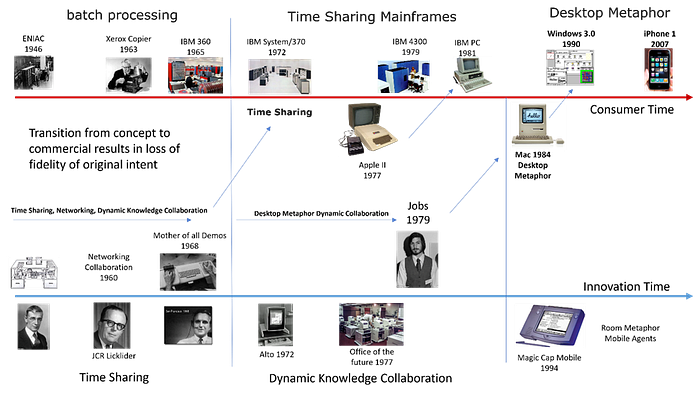
Steve Jobs, accomplished what the team at Xerox Parc could not: take the incredible innovations and bring them to the mass market. In doing, so he only stole part of the incredible work Alan Kay’s team did — the GUI.
A book called “Fumbling the Future“ (Fumbling the Future: How Xerox Invented, then Ignored, the First Personal Computer: Smith, Douglas K., Alexander, Robert C.: 9781583482667: Amazon.com: Book) explores this key inflection point in the formation of modern knowledge systems. Due to limits of the technology at the time, and in the rush to get the Macintosh to market, Jobs stole the wrong thing: He only took the look and feel of the Alto. He did not replicate the much deeper and more powerful knowledge creation and collaboration platform Alan Kay and his team had created with Smalltalk.
The result was: “You wound up with something that was skin-deep compared to what the PARC thing was but had lost the soul of everything being accessible, everything being malleable and so forth, and we never got it back. And that messed things up forever. That messed things up today.” Alan Kay — Valley of Genius (Valley of Genius: The Uncensored History of Silicon Valley (As Told by the … — Adam Fisher — Google Books)

The challenge was that the technology at the time was too limited to create a personal computer that was cheap enough for people to buy, while still making it powerful enough to run even the most rudimentary application.
The Alto computer, developed at Xerox PARC, and its accompanying Smalltalk programming language, represented a paradigm shift in how computers handled programs and content. Unlike the later model of separate applications and file or database storage, the Alto and Smalltalk employed a more integrated approach. (The Early History Of Smalltalk (worrydream.com))

In the Alto’s model, programs and data were not treated as distinct entities but were interwoven. Smalltalk, as a programming environment, was designed to be highly interactive and object-oriented. This meant that everything in the system was treated as an object, including both data and the programs that manipulated that data. This approach facilitated a more seamless interaction between different software components and the user, making the computing experience more intuitive and fluid.
This integration of programs and content allowed for a more dynamic interaction. Users could manipulate objects directly through a graphical user interface (GUI), which was a groundbreaking feature of the Alto. The GUI made computing more accessible and user-friendly, setting the stage for future developments in personal computing.

However, when Steve Jobs and Apple took inspiration from the Alto to develop the Macintosh, they faced technological constraints that weren’t as pronounced at Xerox PARC. These limitations, such as memory and processing power, necessitated a shift towards the more compartmentalized model of separate applications and files. This model, while less integrated than what the Alto and Smalltalk offered, was more feasible with the technology available at the time and more suited to the consumer market.
Thus, while the Macintosh successfully popularized the GUI and brought many of the concepts from the Alto to a broader audience, it did so by adapting the Alto’s more integrated model of programs and content into a format that was technically and commercially more viable at the time.
Alan Kay described as the Alto as the ‘Interim Dynabook’ — the idea being that the team were well aware of the fact that limitations in technology had meant creating compromises. The compromises were never supposed to become broadly adopted standards. One of these compromises was the adoption of the ‘File’ and the ‘Folder’ pattern as a means of storing documents created on the Alto.
I was able to track down the original documentation for the Alto’s file system, which calls out the core issue with files and folders being a poor means of storing key knowledge:
”The facilities for identifying files are not ideal, but you will get used to them after a while. Better facilities are the subject of research.”

Unfortunately, data coupled to a specific application pattern that Jobs cloned in creating the LISA and Macintosh spread to Microsoft’s Windows. The result was the Application + Data silo pattern became the standard method of developing knowledge systems.
We now suffer from the fallout of the compromises made to commercialize Xerox work every single day. I still hear senior leaders in organizations talking about how they need to create the types of ‘Standards’ described in this 1976 Alto Manual to solve challenges of knowledge storage and retrieval. I have never seen a purely standards based pattern that actually works at scale.

We have literally been frozen in time: sinking in a myriad of applications that don’t communicate or share data with each other, gigantic unwieldy file stores, users struggling to get answers to even simple questions.
Datalakes and other powerful new technologies certainly have started to help on unifying structured and unstructured file based data into a form amenable to answering questions, but they are a response to the problem that treats only the symptoms, not an actual foundational solution.

AI is the OS: How AI has the potential to help
The work at Xerox Parc that was not copied in the commercialization of the GUI, were the deeper elements associated with the knowledge creation, curation and collaboration.
In traditional programming environments, there’s a clear division between the static aspects of program code, such as class definitions and functions, and the dynamic, runtime state, including objects and data.
What this has lead to is the horrific complexity people experience every day trying to even do simple things with their data using applications. For example, trying to get your bank statements from your bank’s App, sort the data from the statements into categories, and then submit the data from specific categories into your accounting system is an incredibly challenging and time consuming process.
Smalltalk is designed merge program data and code into a unified framework. This innovative method sought to create a more integrated and fluid computing experience.
Messaging enabled the objects and the content they contained to move and flow freely across application boundaries seamlessly if the user had permissions to manipulate the objects.
In our banking example, the user would simply have asked the banking app from the spreadsheet with Smalltalk code to get the statements, sort them into categories and then send data from specified categories as objects via a message to the accounting system.
Alan Kay has commented that despite the attention given to objects, messaging is the most important concept in Smalltalk: “The big idea is ‘messaging’ — that is what the kernel of Smalltalk/Squeak is all about (and it’s something that was never quite completed in our Xerox PARC phase).” (Smalltalk — Wikipedia)
AI and Large Language Models have the potential to break the tyranny of the Application + Data silo pattern that has become a barrier realizing the potential of the power of knowledge augmentation.
Large Language models can turn natural language into code like a compiler, opening up tremendous opportunity for anyone to provide the instructions rather than relying solely on programmers (LLMs → The Next Compiler. “LLMs are poised to revolutionize… | by Mike Morley | Medium). Large Language Models are also capable of blending code through prompts combined with ‘data’ that is the Knowledge Asset into a unified object that can be sent via message to Agents who can then take action.
Imagine if an operating system were created that fully harnessed this potential — one that was based on the principles of Smalltalk.
By abstracting the complexities of code and algorithmic logic into conversational commands, an LLM ‘OS’ could significantly lower the entry threshold for application development and knowledge creation. This shift towards more natural interfaces could catalyze a new wave of personal computing, where creating and sharing knowledge-based applications becomes as simple as describing one’s needs or ideas to an AI assistant.
In this context, LLMs can bring back the Knowledge First spirit of Smalltalk. The encapsulated data and tightly coupled application paradigms that currently dominate software development could give way to a more fluid, modular, and knowledge-centric model.
The first attempt at this that I have found thus far is the Rabbit-os Large Action Model (LAM). The LAM model has been trained to operate application user interfaces, acting as a proxy for the user.
Large action models in programming and AI research are conceptual frameworks that aim to integrate programming (action) and content (data) into a seamless whole.
Large action models harken back to Kay and Engelbart’s original visions by striving to create computing environments that are more than just tools for executing predefined tasks. Instead, they aim to be dynamic spaces for exploration, learning, and creation, where the boundaries between code and content are blurred. This approach encourages a more holistic interaction with technology, where users can engage with and contribute to their digital environments in a deeply integrated manner.
Using LLMs, individuals could compose complex functionalities by stringing together simple, descriptive requests, thereby fostering a more inclusive and collaborative digital ecosystem. This not only aligns with Alan Kay’s vision of computers as a medium for creative expression and learning potentially enabling anyone to harness the power of computing to create and share knowledge far more easily than ever before.
LLMs when combined with emerging patterns such as Retrieval Augmented Generation, have the potential to break down the tyranny of the tightly coupled application/data/file nightmare we have inherited.
Risk of history repeating itself…
However, there is a tremendous risk of history repeating itself. In the rush to commercialize AI technology, one of the things that has already occurred is the deployment of the model capabilities without consideration for the people whose knowledge compose the foundations of the data necessary to train the models.
Historically people have not understood the true value of their data as the lifeblood of large technology companies. With the rise of AI and LLMs, people (the first wave being artists) are now waking up to the fact that not only have their valuable data been used to train AI models, the models have the potential to replace them.
Companies using these data have raced to create the technology with limited thought of a means of crediting or compensating the original creators.
Companies developing large language models (LLMs) do indeed face significant challenges in compensating creators whose content contributes to these models’ training. The vast scale of data, often comprising billions of words from diverse sources like books, articles, and websites, makes it logistically challenging to track and attribute individual contributions. Furthermore, much of this data lacks clear authorship information, complicating efforts to accurately identify and compensate creators. Legal and licensing complexities, alongside the transformative nature of AI training processes, further obscure the direct lineage from specific inputs to AI outputs. These factors, combined with the economic models predicated on the free acquisition of training data, present substantial barriers to direct compensation.
Despite these hurdles, there is an increasing call within the tech community for ethical AI development practices that include fair compensation for content creators. The discourse is evolving towards exploring new frameworks for attribution and compensation, recognizing the need for copyright reform and the development of AI-specific laws. Potential solutions being considered include collective licensing agreements and revenue-sharing models, aiming to balance the economic realities of AI development with the rightful acknowledgment and reward for creators. This shift reflects a broader recognition of the value of creative contributions to the advancement of AI technologies and the importance of equitable practices in the digital economy.
The rush to commercialize the technology though has once again resulted in risking limiting its potential to truly make people’s lives better instead of simply treating people as a means of funding.
Imagine if instead of simply absorbing all the available content on the internet, companies creating LLMs had taken the time to also figure out a way of renumerating and crediting creators with their contributions to the training data.
Imagine if they had created a ‘Knowledge Vault’ — a system that enable people to capture and curate their Knowledge Assets into a well formed, curated form that LLM training could have used as a reliable source of training data for their models. This would have benefited the creators by making it easy for them to leverage LLM technology for Augmenting their work processes, while also giving them the opportunity to ‘lend’ or ‘lease’ their Knowledge Assets to organizations for training Large models, or fine tune domain specific models. (I will have to explore this more in a separate post.)
Final Thought for now.
When I speak to people about technology, people assume that the knowledge systems we work with were created to be the way they are by design instead of by compromise and commercial interests.
There are vanishingly few people, even in the technology domain who are aware of the work done by those like Alan Kay, Douglas Engelbart, J.C.R. Licklider and other visionaries who contributed before the cementing of the GUI/App/Database/File knowledge pattern into the collective consciousness.
My personal view on this is that all computer and data scientists should take a history of computing course to provide a background and understanding of where our systems emerged from and why. I also think an ethics course would be useful training as well, similar to what is done in the applied engineering domain to help with considering questions about who will be affected, and how the challenges could be mitigated before releasing the code to the world.
We have a unique opportunity to recapture the vision of the ‘Dynamic Knowledge Repository’ as envisioned by Douglas Engelbart, and further developed and realized by Alan Kay and others at Parc. My hope is that through helping to spread the word about what has gone before, what we have lost and to demand and develop systems that truly enable Augmenting the Human Intellect…
Imagine what we could know..
— — — — — -
References:
VANNEVAR BUSH As We May Think →1945
Dynamically Capture and easily share my knowledge
A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.
He has dozens of possibly pertinent books and articles in his memex. First he runs through an encyclopedia, finds an interesting article, leaves it projected. Next, in a history, he finds another pertinent item, and ties the two together. Thus he goes, building a trail of many items. Occasionally he inserts a comment of his own, either linking it into the main trail or joining it by a side trail to a particular item.
Following world war 2, Vannevar Bush expresses his concern for the direction of scientific efforts toward destruction, rather than understanding.
He saw an opportunity for scientists to direct their efforts to the massive task of making more accessible the ever growing store of knowledge.
Through the memex outlined in as we may think, Bush hoped to transform an information explosion into a knowledge explosion.
JCR LICKLIDER Man Computer Symbiosis: 1960
About, 85 per cent of my ‘thinking’ time was spent, getting into a position to think, to make a decision, to learning something I needed to know. Much more time went into finding or obtaining information than into digesting it.
No two experimenters had used the same definition.. Several hours of calculating were required to get, the data into compatible form. When they were finally comparable form, it took only a few seconds to determine what I needed to know.
If those problems- can be solved in such a way as to create a symbiotic relationship between man and a fast, information — retrieval and data-processing machine, however, it, seems evident, that the cooperative interaction would greatly improve time spent thinking…
Contribute and annotate data to informal notes and comments.
Eliminate data silos by automatically integrating data
providing easy to use languages and techniques to users so that they can customize their environments
I can focus on improving my knowledge — not wasting time assembling data
Douglas Englebart Augmenting the Human Intellect 1960
have definitions automatically substituted for the other’s special terms. Reduce this language barrier, and provide the feature of their being able to work in parallel independence on the joint structure, and what seems to result is amplification.
Three people working together in this augmented mode seem to be more than three times as effective in solving a complex problem as is one augmented person working alone — and perhaps ten times as effective as three similar men working together without this computer-based augmentation.
Real time dynamic knowledge collaboration, across all devices and platforms
Ted Nelson A File Structure for The Complex, The Changing and the Indeterminate 1965
THE KINDS OF FILE structures required if we are to use the computer for personal files and as an adjunct to creativity are wholly different in character from those customary in business and scientific data processing. They need to provide the capacity for intricate and idiosyncratic arrangements, total modifiability, undecided alternatives, and thorough internal documentation.
the file system that would have every feature a novelist or absent-minded professor could want, holding everything he wanted in just the complicated way he wanted it held, and handling notes and manuscripts in as subtle and complex ways as he wanted them handled.
If a writer is really to be helped by an automated system, it ought to do more than retype and transpose: it should stand by him during the early periods of muddled exploration, when his ideas are scraps, fragments, phrases , and contradictory overall designs. feasible mechanical aid — making the fragments easy to find, and making easier the tentative sequencing and, juxtaposing and comparing.
To the user it acts like a multifarious, polymorphic, many-dimensional, infinite blackboard.
Transcend the limits of paper to store the true ever changing dynamic nature of knowledge
Alan Kay A personal computer for children of all ages 1972
We need a uniform notion as to what objects are, how they may be referred to, and how they can manipulate other objects.
The evaluation of a control path should follow simple rules which show how objects are passed messages and return results.
Every object in a system should be redefinable in terms of other objects.
Present to a user a very simple programming language nonetheless, is capable of a wide variety of expression. Technology can provide us with a better “book”, one which is active (like the child) rather than passive. It may be something with the attention grabbing powers of TV, but controllable by the child rather than the networks.
A safe environment, where the child ‘can assume almost any role without social or physical hurt is important….
My data an my devices serve me — not the data industrial complex.
“Should the computer program the kid, or should the kid program the computer?”
-S. Papert
